
How CDN Switching Blind Spots Lead To Rebuffering
Reducing video rebuffering can be difficult. One solution that many people are talking about these days is moving to a multi-CDN architecture, a topic I’ve written a lot about. But will going multi-CDN magically reduce your rebuffering and drive away all of your streaming ills? The answer, of course, is complicated. Going multi-CDN can provide several benefits for customers, such as better geographic coverage and, possibly, better economics. Adding live switching logic between the CDNs goes a step further and enables load balancing and redundancy in case of problems. But what are the problems that customers are likely to encounter? Let’s examine some common CDN problems and their impact.
Catastrophe and Chaos
Once in a blue moon, a CDN will experience a major outage that affects a large geographic area. These outages are so extreme that they shut down a large portion of the Internet for a non-trivial amount of time. Recent examples of such outages:
- June 2, 2019 – Google Cloud Platform multi-region 4 hours outage
- July 24, 2019 – BGP Routing issue as described on Cloudflare’s Blog
Detectability: Very easy to detect as any metric that you care to measure will explode. Your alerts will fire or, if you don’t have alerts, you’ll get messages and phone calls from users.
Solution: A good CDN switching engine will attempt to re-route users to a working CDN within the limits of the outage.
PoP Flop
Occasionally, a CDN might experience a local issue in one of its PoPs (Point-of-Presence), which means all of the users that are routed through that specific PoP will have problems fetching video segments, and will most likely experience rebuffering.
Detectability: Medium or hard depending on the percentage of users that are affected. A large portion of the traffic would skew the metrics enough to create an anomaly, while a small portion might get swallowed within the geographic granularity of the monitoring system.
Solution: A good CDN will re-route the impacted traffic to a different PoP within its network which will cover for the faulty PoP with best-effort performance. A good CDN switching engine will eliminate the faulty CDN altogether from that region and just use a non-faulty one.
Smaller scale outages are so hard to detect that you might never know they ever happened. Have your users experienced such an outage? The answer is most likely yes, since all CDNs see dozens of them as part of their daily monitoring efforts. In the industry, we call these events “blind spots”.
The Blind Spots of CDN Switching
There are 3 main blind spots that server-side CDN switching engines do not address very well:
- #1. The DNS Propagation Problem. “We already know there’s a problem, but we have to wait at least 5-10 minutes for DNS to propagate.” A common CDN switching implementation is based around DNS resolving. The DNS resolver incorporates a switching logic that responds with the best CDN at that given moment. If one of the CDNs in the portfolio experiences an outage or degradation, the DNS resolver will start responding with a different (healthy) CDN for the affected region. The blind spot of DNS would be its propagation time. From the moment the switching logic decides to change CDNs, it might take several minutes (or longer) until the majority of traffic is actually transitioned. Moreover, while most ISPs will obey the TTL (DNS response lifetime) defined by the DNS resolver, some will not, causing the faulty CDN to remain the assigned CDN for the users behind that ISP. Rebuffering on existing sessions is inevitable, at least until the DNS TTL expires on the user’s browser.
- #2. The Data Problem. “We select CDNs based on a synthetic test file, but real video delivery is much slower.” Any switching solution must implement a data feed that reflects the performance of the CDNs in different regions and from different ISPs. A common approach for gathering such data is to use test objects that are stored on all of the CDNs in the portfolio. The test objects are downloaded to users’ browsers, which then report back the performance that was observed. Often times, for various reasons, the test objects don’t represent the actual performance of the video resources. For example, imagine that the connection between the origin and the edge server is congested – the test object will not be impacted since it’s already warmed in the cache of the edge server and does not need to use the congested middle mile connection to the origin. This performance gap will cause a CDN to be erroneously selected as the best one even though the reality differs. It’s also possible that the test objects and the actual video resources do not share the same CDN bucket configuration. If the video resources bucket is misconfigured, some users might get unoptimized or even faulty responses which at no point will get detected because the test objects bucket functions properly. This kind of disconnect between synthetic performance measurements and actual delivery performance often generate degraded performance that gets undetected for a very long time.
- #3. The Granularity Problem. “We select CDNs based on overall performance in each region, but this stream is performing poorly for a subset of the users.” A typical CDN Switching flow might be:
• measure CDN performance across different regions• report results to the server• server chooses the “best” CDN• users are assigned to the best CDN for their region
Unfortunately, not all regions have fresh performance data all the time and so a fallback logic is usually applied. When there isn’t enough data in a specific region, data from its greater containing region will be used instead. It’s possible that a region with small amount of users gets swallowed up by a larger fallback region, in which case an outage might not be detected at all because the affected users comprise a small portion of total traffic that is not enough to “move the needle”.
This is a data granularity problem. A broadcaster might have 100k users that are spread across 15 countries, 1,000 unique regions, 5,000 ISPs and a host of other parameters. Taken together, these parameters segment the user base into millions of tiny dimensions, none of which will have enough data to perform meaningful switching decisions, not to mention the load it will create on the switching system. For this reason, server-side switching is inherently limited to a more coarse grouping that is technically and mathematically viable. This reality creates a blind spot when it comes to smaller regions that might get hit by a local, undetectable outage.
Real World Example of The Granularity Problem
In the last week of August, an outage occurred in the U.S. which demonstrates the granularity problem. An outage by a CDN I won’t name, caused a significant drop in request performance that, in turn, led to rebuffering. Thanks to Peer5 for sharing the screen grabs (below) from their monitoring tool showing that at 7:20 AM, an increase in Time-To-First-Byte(TTFB) was observed from an average of 850ms to a peak of 6700ms. When comparing the 95th percentile TTFB of the affected area to its greater containing region, it’s clear that the affected area didn’t constitute enough data to move the overall metric.
95th Percentile TTFB – Affected area vs Greater Region
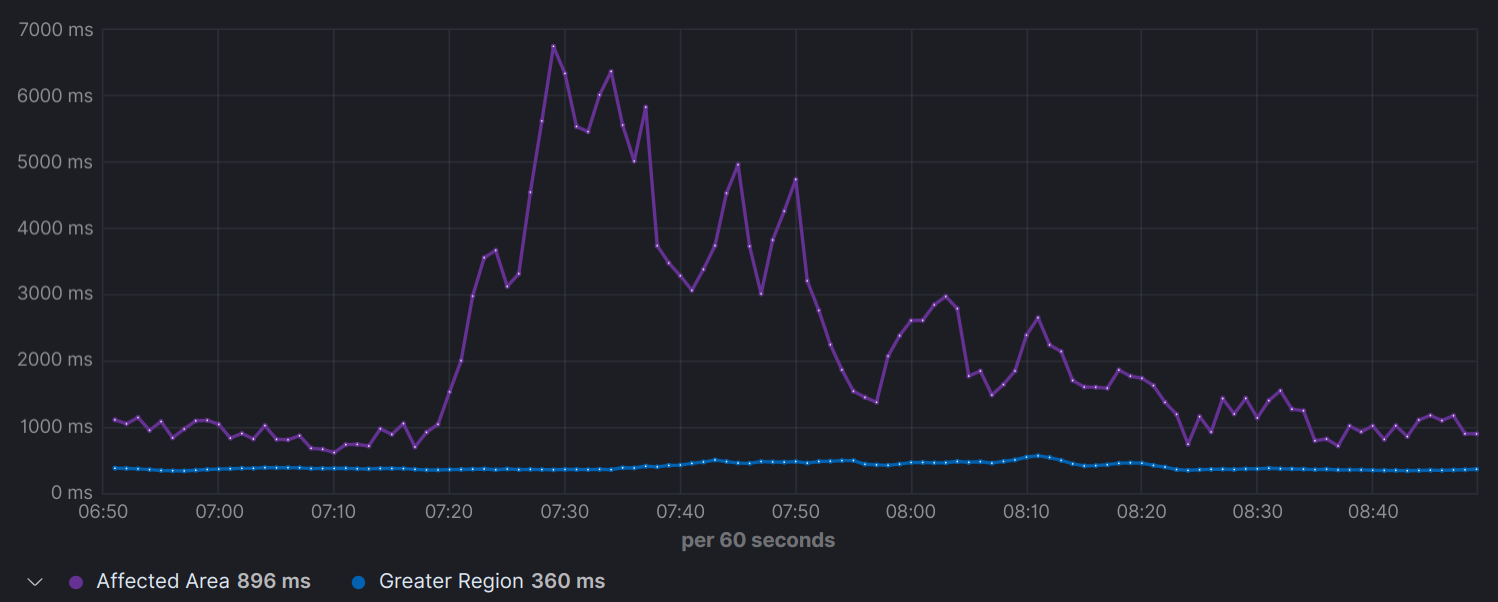
The greater containing region (blue) doesn’t show any anomalies throughout the outage. (less is better)
Rebuffer Time as %
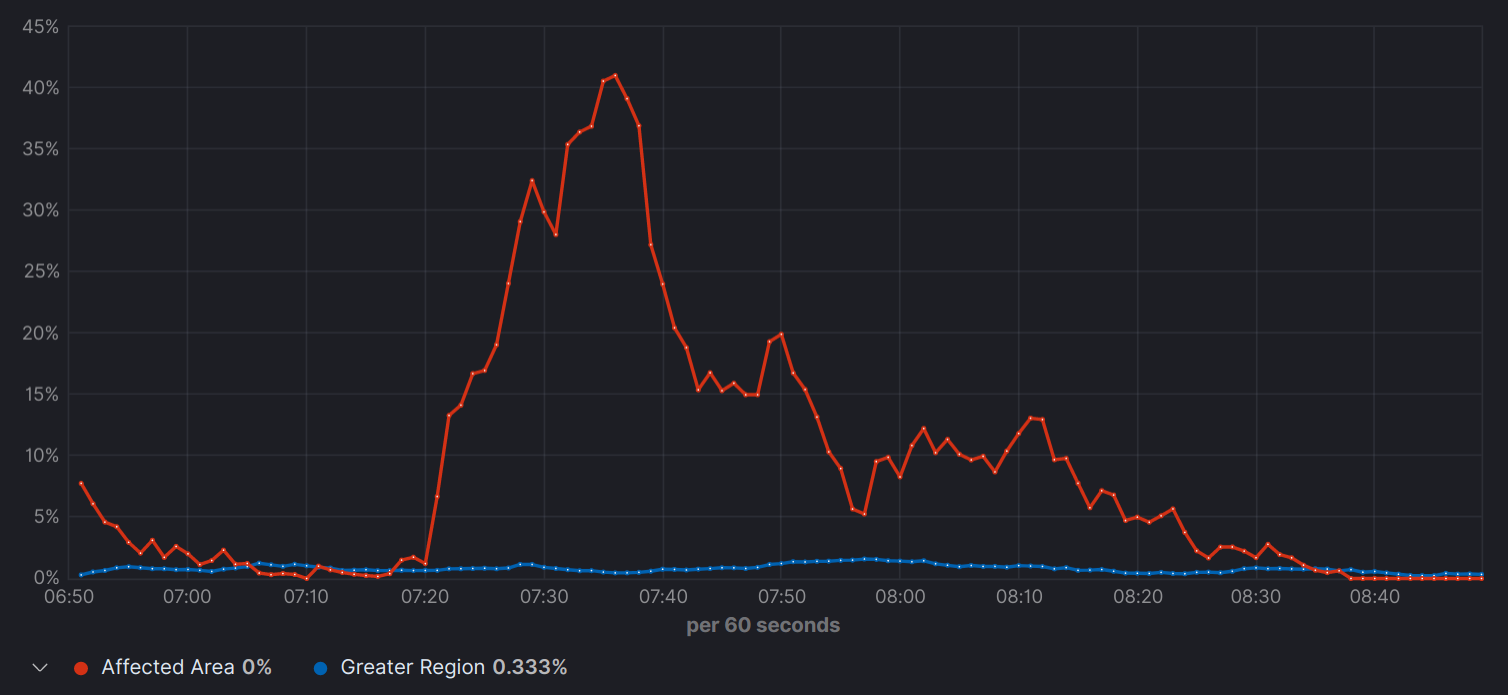
Rebuffering spikes render the playback unwatchable. (less is better)
Allocated CDNs Over time
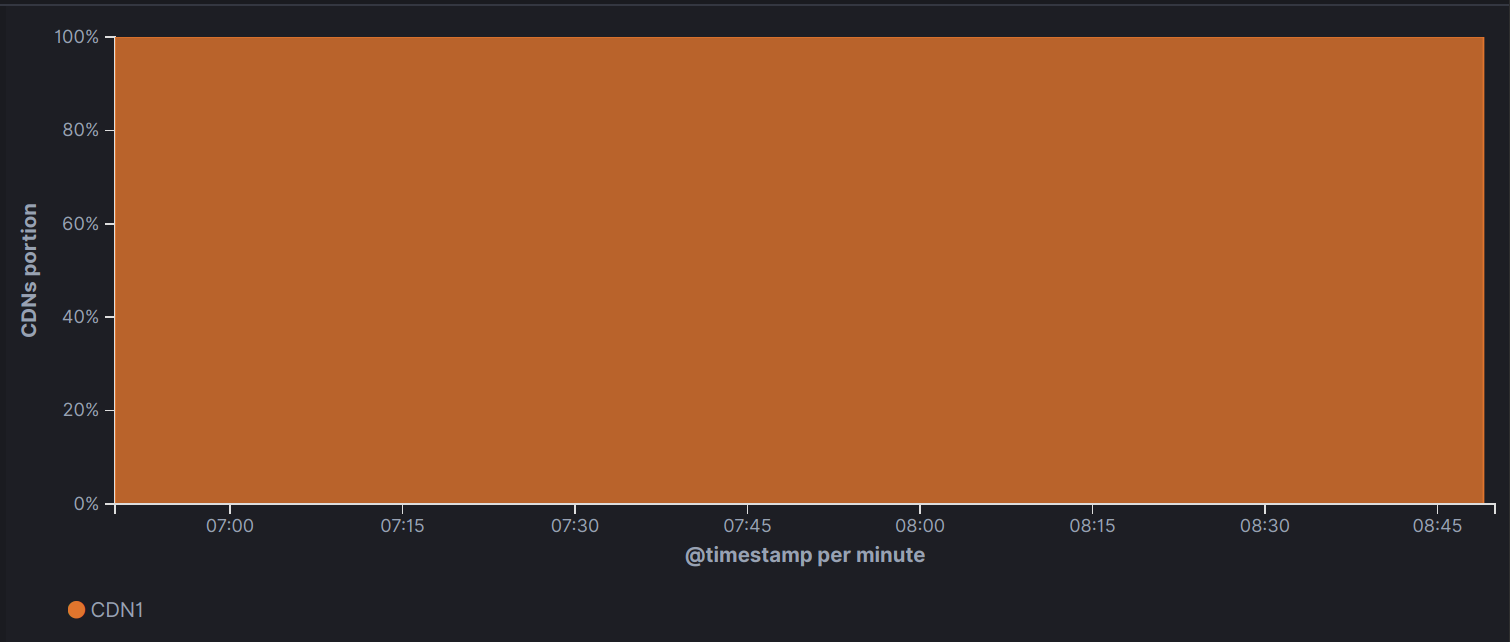
While this chart might seem dull, it illustrates the fact that throughout the entirety of the outage, no CDN switching took place for the given region.
Enter: Per User CDN Switching
Video playback is a very fragile thing. A user might have just a couple of seconds of content buffered ahead and any slowdown in fetching segments can easily consume that buffer and freeze the playback. For this reason, vendors in the market are coming up with ways to fix the problem. For instance, Peer5 created a client-side switching feature which constantly monitors the playback experience for each individual user and is able to react to poorly performing CDNs within a split second (literally, milliseconds) and prevent rebuffering from ever happening. This means that even an outage that only affects one user will be accounted for. The below charts shows the performance during the outage described above with and without a client-side switching feature.
95th Percentile TTFB – Affected area vs Greater Region
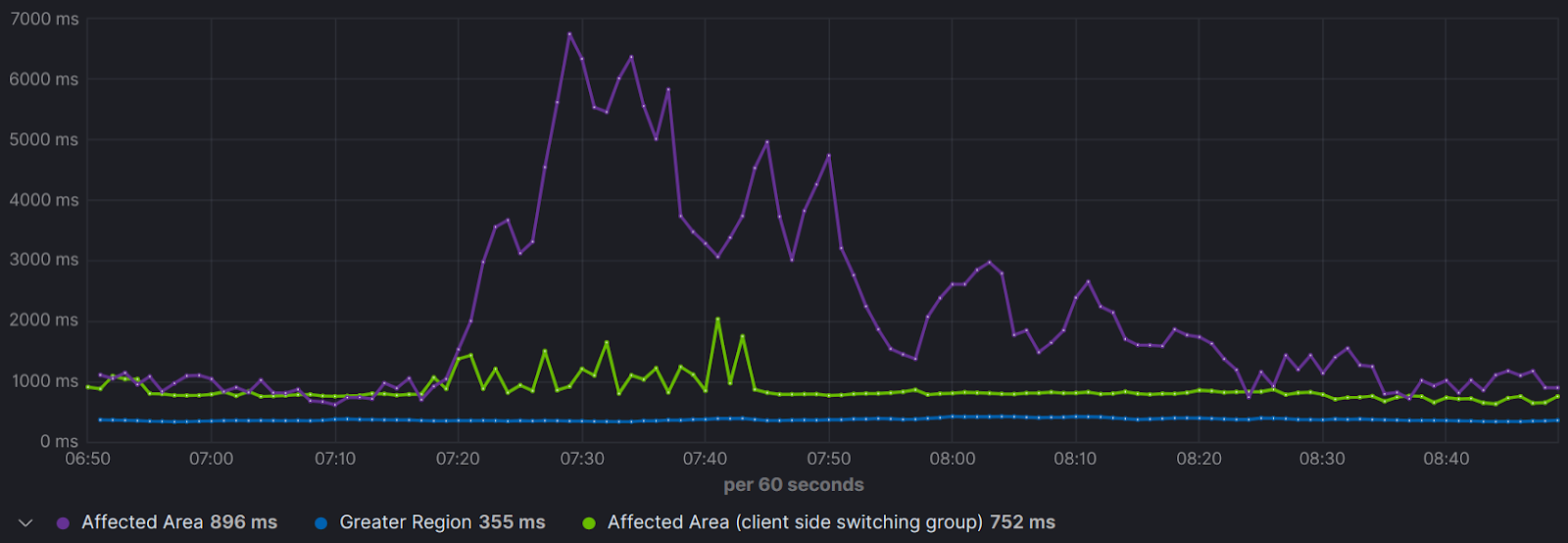
The TTFB of the client-side switching group (green) was affected as well but much less than the other group. (less is better)
Rebuffer Time as %
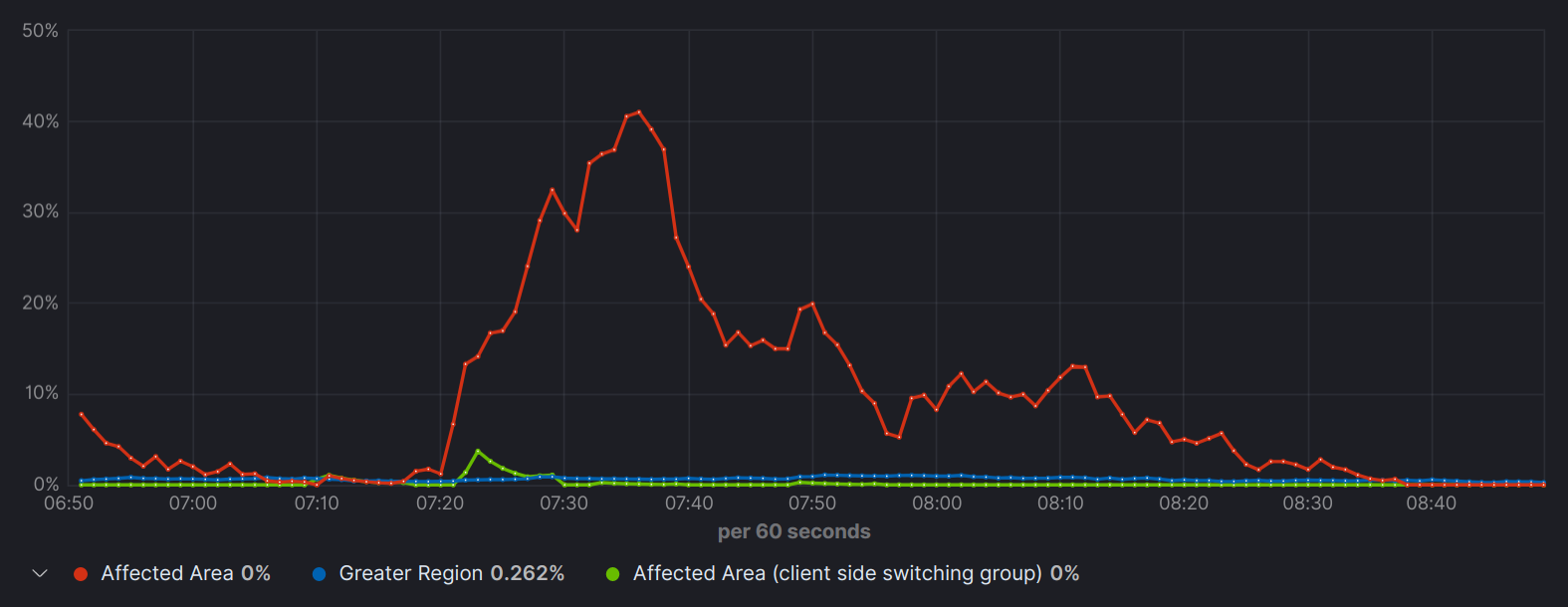
The client-side switching group (green) experiences almost no interruption in playback. (less is better)
As seen in the graph above, users that relied solely on server-side switching (red line) were impacted significantly, compared to users with client side switching. Server-side CDN switching was not granular enough to detect the local outage and the assigned CDN for that region remained the same even though some users experienced terrible performance degradation. The client-side switching, with its per-user granularity, was able to change the mixture of CDNs within the region and avoid the issue in real-time. The rebuffering was reduced from 11.2% to 0.2% for client-side switching enabled users, and the overall region rebuffering was reduced by 70% from 1% to 0.3%.
Summary
When CDNs experience outages, users will encounter rebuffering. There are multiple types of outages, some will go below the radar completely undetected while some will make you notice them immediately. Different layers of redundancy and different levels of granularity tries to address the various outages an online delivery pipeline might experience. A combination of several such redundancy tools is likely to achieve the best UX. Employing server-side switching alongside client-side switching allows customers to:
- Reduce rebuffering by monitoring video playback constantly for all users
- Allow existing sessions to respond to outages very QUICKLY by switching CDNs on a per request level
- Improve bitrate and quality by increasing the granularity of CDN selection to a per-user level
There’s lots of ways to solve the video buffering problem depending on what type of video you are delivering, (live vs VOD), the platform or devices you are delivering it to and the user-experience you are looking to achieve. What’s your take on the best ways to reduce video buffering? Feel free to leave them in the comments section.