The Technology Behind Comcast’s 30 Mbps Upscaled 4K Super Bowl Stream

In conjunction with Super Bowl LX, Comcast’s Xfinity announced the launch of what they call “RealTime4K”, a new ultra-low-latency technology with a 30 Mbps bitrate supporting Dolby Vision HDR and Dolby Atmos, compatible with an Xfinity X1 XG1v4 or Xi6 TV Box, or an XiOne streaming TV Box for Xfinity Flex. Comcast is positioning RealTime4K as a 4K delivery architecture designed specifically for premium live sports and optimized for both speed and visual fidelity. Unlike traditional 4K streams that rely heavily on compression, the technology is engineered to reduce latency while maintaining high-bitrate video and immersive audio formats. While the brand name to consumers uses the term 4K, it’s important to note that it is not native 4K and that Comcast’s source feed is 1080p HDR.
Comcast’s RealTime4K uses DASH and HLS to stream to set-top boxes, and via the Xfinity Stream app, compatible customer-owned streaming devices (Xumo Stream Box, Apple TV, Fire TV, Roku, Samsung and LG TVs) can also get the 30 Mbps stream but without the ultra-low-latency functionality. Comcast set-top boxes further use low-latency DASH (LL-DASH) to remove delays introduced by segment packaging and client-side buffers.
For the encoding pipeline, Comcast uses HEVC and Dolby Vision Profile 8.1, with a bitrate ladder that caps at 30 Mbps and supports full 4K resolution on both the first and second rungs. And since last year’s Super Bowl, Comcast has integrated the latest Dolby Vision improvements into its encoding pipeline. For audio encoding, Comcast RealTime4K always includes Dolby Atmos, natively produced when available from the content provider and, otherwise, upmixed by Comcast. Comcast encodes Atmos at 768 Kbps and delivers it as DD+JOC.

For Super Bowl LX, Comcast partnered with NBCUniversal and used a JPEG-XS source feed. Typical 4K live events are compressed to 50-70 Mbps using HEVC before being sent to distributors. Using JPEG-XS at over 300 Mbps allowed Comcast to avoid a generation of HEVC encoding, significantly improving picture quality and reducing latency by about 5 seconds in the video production pipeline.
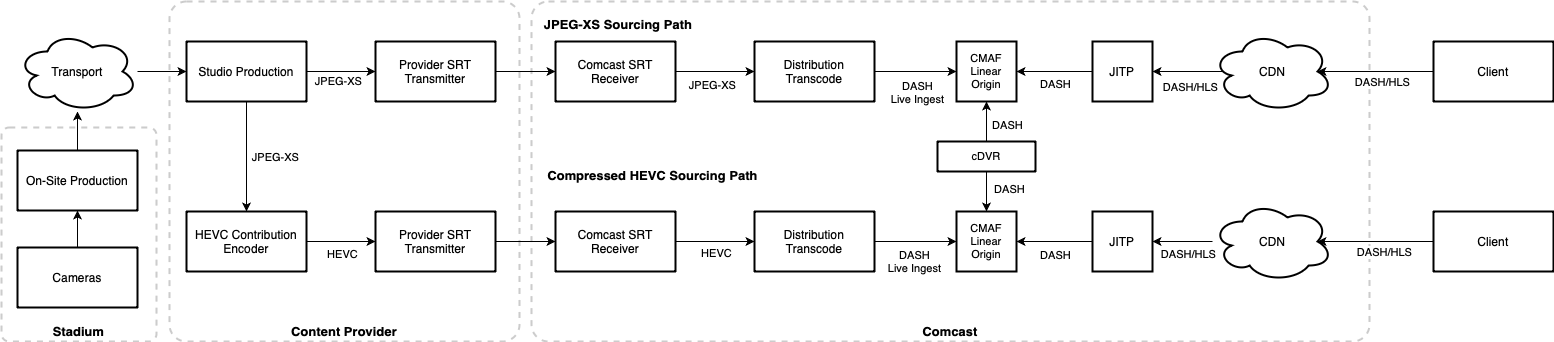
The core of Comcast’s RealTime 4K video pipeline is a DASH live ingest, powered distribution transcoder, and CMAF linear origin. The transcoder accepts JPEG-XS as input (or HEVC mezzanine when JPEG-XS isn’t available) and generates all needed renditions while minimizing overall delay. The transcoder publishes each chunk of media, as it is encoded, to the CMAF linear origin. The origin provides access to DASH manifests and segments to both the just-in-time packager (JITP) for live playback and Comcast’s Cloud DVR system. Comcast has partnered with MediaKind for transcoding while building its own CMAF linear origin and JITP. For Super Bowl LX, Comcast used its on-premises CDN to deliver the RealTime4K feed, but also uses the same LL-DASH video architecture to power partner systems using public CDNs such as Akamai and CloudFront.
Beyond the architectural claims, Comcast also put RealTime4K into a live, high-stakes environment during a full day of Olympics and Super Bowl coverage, plus streaming coverage on Peacock, making Sunday, February 8, the most-trafficked day ever for video streaming on Comcast’s network. According to internal testing Comcast conducted during the event, the RealTime4K feed on Xfinity delivered latency that was between 9 and 49 seconds ahead of vMVPD streaming services, even as the network experienced its most-trafficked day for video streaming to date, driven by a mix of IP video streams (including the RealTime4K feed) and streaming on Peacock and other platforms. During my testing of the Super Bowl LX stream, I was unable to test Comcast’s RealTime4K latency myself, as I am not in Comcast’s footprint; otherwise, I would have included them in my Super Bowl LX latency chart.

As of today, Comcast RealTime4K technology is free for all customers, with the primary limitation being the hardware requirements for the ultra-low-latency verison of the stream. For customers who do not currently have compatible hardware, the company is offering device swaps to 4K-enabled Xfinity equipment at no additional cost. Customers can also visit a nearby Xfinity store to exchange their existing X1 TV box for a 4K-capable one.
Comcast is positioning RealTime4K as the preferred delivery model for live 4K events going forward, not just for showcase events like the Super Bowl, and is already in talks with other programming partners to bring this technology to their live 4K events this year. The company has also emphasized its ongoing commitment to continuous network improvement, focusing on further optimizing delivery, throughput, and video pipelines to push the limits of video quality, latency, and immersive live-viewing performance.
If you have had an opportunity to check out the RealTime4K tech at your home, please feel free to share your experience in the comments. I’ll be hands-on with the technology and offering soon, and will provide updates to this post once I see it in person.